Lately I see linkedin full of diagrams trying to explain the “AI stack”. The problem is that almost none of them are designed around how BI teams actually work.
From a BI point of view, many of those explanations are technically confusing and, even worse, they add very little value when it comes to explaining to the business what is happening and why it matters. In BI we do not just think about technology. We look for clarity to connect data with real pipelines, real teams, and business decisions.
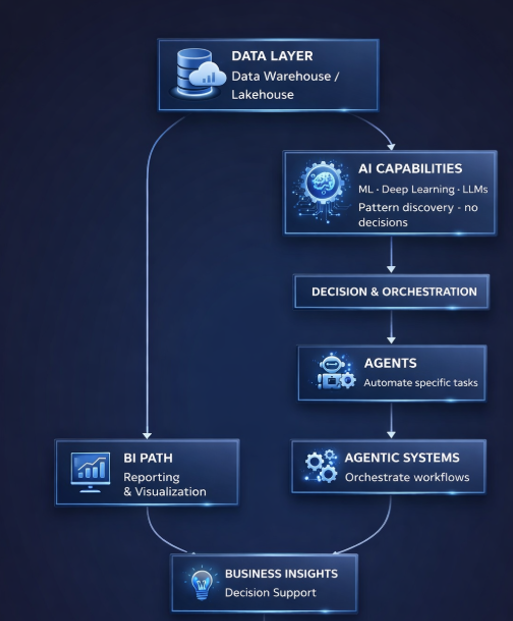
So here is my own version of the AI stack, based on how I see BI teams actually operating today.
Data Foundation — Warehouse / Lakehouse
This is the foundation of the entire stack. This is where organizations collect data coming from ERPs and operational systems: transactional, historical, and operational data. It is where ETL and ELT processes are designed and executed, multiple sources are integrated, and data is transformed so it has consistent definitions and a minimum level of governance.
It is not the sexiest part of the stack, but it is by far the most critical one. Without a reliable, structured, and understandable data foundation, any attempt at advanced BI, machine learning, or automation ends up being fragile. From this base, an important split appears.
Business Intelligence — Reporting & Visualization
Business Intelligence lives at the same level as prediction and models, but it serves a completely different purpose. While models look for patterns, BI is responsible for translating data into a narrative that the business can understand.
This is where metrics and KPIs are defined, dashboards and reports are built, results are compared against history, budgets, or benchmarks, and, most importantly, where we explain what is happening, why it is happening, and what decisions should be made. This is the point where data turns into context and where most day to day decisions actually happen. That is why, in practice, BI is usually run by teams different from machine learning, with a focus much closer to the business and decision making than to model optimization.
Machine Learning — Prediction & Patterns
On the ML side you usually find data science or analytics profiles with a strong background in math, statistics, and programming. Their focus is on discovering patterns through machine learning models, such as forecasting or classification.
Advanced ML & Deep Learning
Then we move into deep learning. Here I am intentionally oversimplifying: in a BI context, this layer usually becomes more relevant when there are very large volumes of data or complex use cases, for example banking or large scale retail. Still, deep learning also covers NLP, vision, audio, and other domains, beyond strictly transactional data.
LLMs & Multimodal AI
On top of deep learning, we have the most popular layer today: LLMs and multimodal AI. It is important to note that LLMs are essentially a specific form of deep learning, mainly based on transformers, but with language and reasoning capabilities that make them especially visible to the business.
This is where the magic starts. Today there are many LLMs available, but some of the most popular ones are ChatGPT, Gemini, Claude, and Grok. These models are used for reasoning over text and images, data vectorization through embeddings, multimodal analysis, and even SQL analysis.
Agents — Automated BI Insights
Agents are starting to gain a lot of attention. There is a clear interest in automating processes, because many organizations see them as an opportunity to scale analysis and reduce operational friction. In some cases, people even talk about “replacing people” as if it were as simple as switching tools.
An agent is not just an LLM connected to data. It is a piece of software with multiple components. In general, it needs to decide which data to analyze, which queries to run, execute those queries automatically, interpret results, prioritize which findings matter for the business, and generate actionable insights without direct human intervention.
From a BI perspective, an agent no longer just shows a dashboard. This type of work, which used to require an analyst manually reviewing charts, can now be executed autonomously. That is exactly what I tested in my latest demo published on carmonex.com.
One important point: an agent can invent logic if it is not controlled, but when it is well designed, it should not. It must operate within clear rules and guardrails: allowed queries, defined structures, and parameters controlled by the BI team. When designed correctly, it is often more consistent than ad hoc human analysis for repetitive, cyclical, and well defined tasks.
Agentic Systems — Autonomous Analytics Workflows
Finally, agentic systems and here I am speaking from my personal opinion are what I see many organizations aiming for, especially large companies looking to reduce operational costs.
An agentic system is what happens when we stop thinking about a single agent and start thinking about an entire flow made up of more than one agent.
In practice, what is really allowing agentic systems to start scaling in real companies is not just the models, but the rules, contracts, and intermediate layers that connect them to the business. I am talking about things that are far less exciting than LLMs: consistent metric definitions, reusable semantic layers, structured data context, and clear mechanisms that define what an agent can do and cannot do. Without this, many agents remain interesting demos, but fragile and very hard to bring into production. In a BI context, an agentic system integrates governed data in the data warehouse, a catalog of queries and business rules, one or more specialized agents, reasoning cycles, plan, execute, evaluate, refine, and a layer of actions such as writing results back to SQL, refreshing dashboards, or triggering alerts and reports to the right people.
The key difference is this: an agent solves a task, while an agentic system operates an end to end analytics process. From a BI insights perspective, this means insights are generated on a recurring basis, automatically prioritized, stored as data rather than loose text, and integrated directly into power bi or other tools. It stops being just reporting and becomes an active decision making layer: automatable, parameterized, and scoped to the needs of each department or company.
My final view is that many organizations are hungry to jump straight into agentic systems, because they scale across multiple processes, not just insight generation, but they want to get there without solving the basics first:
- Clean data
- Explicit business rules
- Logic outside of dashboards
- Teams used to automating and reporting, and less and less used to explaining what is actually happening
Without this foundation, agents do not scale and agentic systems only amplify the data problems that already exist. That is why I believe the most realistic path is not to replace BI, but to evolve it: start with small agents that automate insights and then build the system around them.
And above all, instead of spending CAPEX on new ERPs, many organizations should invest more in data engineering first, then in BI, and only after that in strong data science teams using advanced AI tools like the ones described here.
Most companies that are shouting “we want agents” today do not even have a decent metrics catalog. Without that, what they are really going to scale is not intelligence, but frustration and a very large token bill.
Leave a Reply